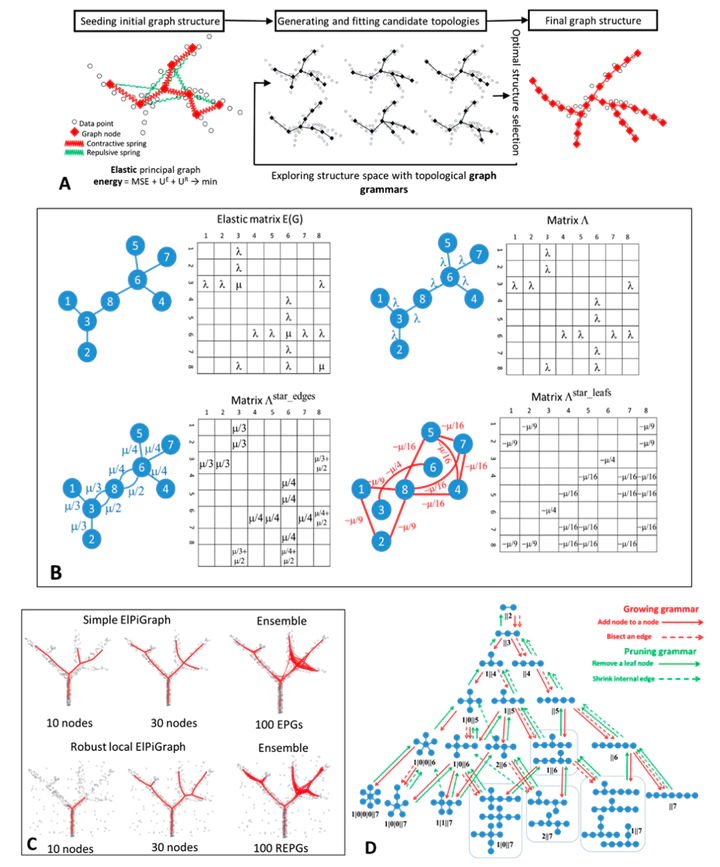
Abstract
Multidimensional datapoint clouds representing large datasets are frequently characterized by non-trivial low-dimensional geometry and topology which can be recovered by unsupervised machine learning approaches, in particular, by principal graphs. Principal graphs approximate the multivariate data by a graph injected into the data space with some constraints imposed on the node mapping. Here we present ElPiGraph, a scalable and robust method for constructing principal graphs. ElPiGraph exploits and further develops the concept of elastic energy, the topological graph grammar approach, and a gradient descent-like optimization of the graph topology. The method is able to withstand high levels of noise and is capable of approximating data point clouds via principal graph ensembles. This strategy can be used to estimate the statistical significance of complex data features and to summarize them into a single consensus principal graph. ElPiGraph deals efficiently with large datasets in various fields such as biology, where it can be used for example with single-cell transcriptomic or epigenomic datasets to infer gene expression dynamics and recover differentiation landscapes.